 |
Established May 1994 | |
| The POVRay benchmark database gives a useful guide to the relative maths
performance of various computers, processors and compilers by timing how long it takes for
POVRay to render a standard image with standard parameters. POVRay is a superb raytracing package that creates stunning images, but it requires as much CPU power as you can throw at it. |
||
|
News PovBench now upgraded! After years of promising to upgrade POVBench to cope with the now astonishingly fast machines, and especially clusters,
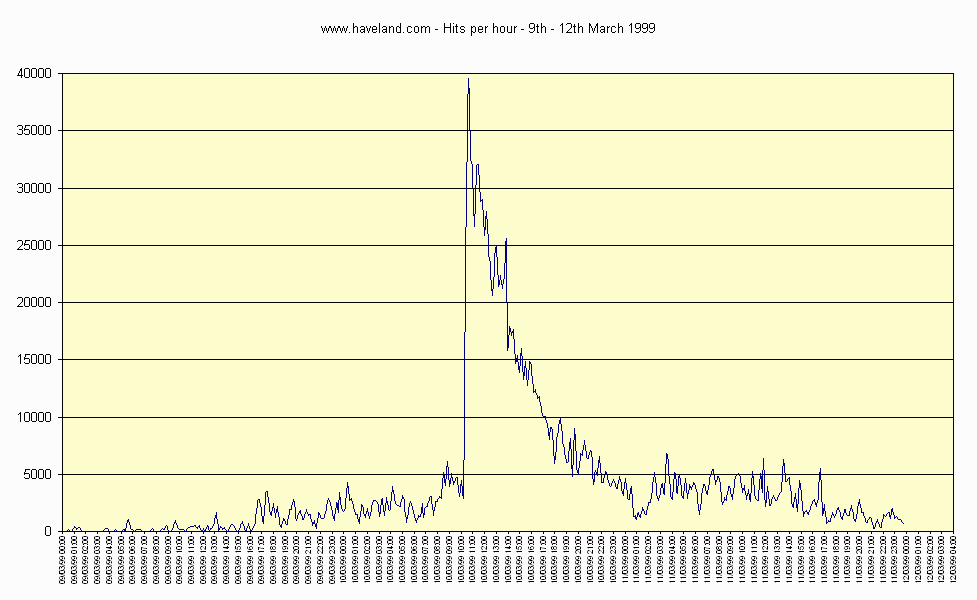
I've finally moved into the 21st Century at last with a proper new database driven benchmarking site using the new more demanding benchmark supplied with PovRay 3.5. Submission and searching is even easier, and I hope prettier - comments and suggestions are welcome. Thank you to everyone who contributed. You make it what it is. August 24 2003 - Beowulf Clusters still hot and getting hotter! At the University of Kentucky, KASY0, a Linux cluster of 128+4 AMD Athlon XP 2600+ nodes, achieved 471 GFLOPS on 32-bit HPL. At a cost of less than $39,500, that makes it the first supercomputer to break $100/GFLOPS. Read more in this article that appeared on Slashdot.com on August 23 2003. Well done to Tim Mattox and the guys at Kentucky. I worry that the benchmark doesn't fully illustrate the enormous power of clusters because each machine in a cluster has to 'waste' so much time precalculating photon maps, as this task cannot be distributed. Note to POVRay authors... Can we have a new benchmark please with minimum latency? Also thanks to Andrey Slepuhin for his AMD Opteron results. August 24 2003 - POVBench redesign imminent! I am updating my whole site to be php based, and not use frames. This may make a few people happier, especially some old Netscape users. Click for a sneak preview! Feedback welcome. March 1999 - Beowulf Clusters are HOT! 'Beowulf' clusters have been gaining in popularity because of their great scalability, price/performance and ease of configuration. NASA created the Beowulf Project a few years ago to try and combine the power of several small PCs into something approaching useful. A 'Beowulf Class' computer has become the term given to a network of Linux PCs that work together as a single parallel computer, with impressive results. Egan Ford and Jay Urbanski of IBM demonstrated one such cluster at LinuxWorld Expo, submitted the results here and made headlines around the world. (As I discovered when this page took 7000 visitors and 200,000 hits in just one day - 100x average! (Here's a chart of the influx which coincided with the Infoworld article.) New Benchmark When I started benchmarking POVRay in 1994, it took hours to render an image with a 386/486, now we can do it in
seconds. It's astonishing just how far we have progressed since those early days. Now we
don't even have time to make a cuppa while the image is rendering! March 1999 saw the addition of 120 interesting new benchmark results, though it was a few months before anyone else matched the 3 seconds set by the Netfinity team. The 62x PII-400 Gravitor I cluster came in at 6 seconds, but the processors were idle most of the time due to communication overheads. The newer benchmark will reduce the significance of these latencies. Some of you may notice that I've summed all of the clusters' individual machines' clock rates to give a virtual clock rate. A little silly perhaps, but it gives an idea of how much processing is lost in overheads when comparing a large network of slow machines with a small network of fast machines. |
{kind=link}
Making a Submission
New Standard POV Benchmark PovRay 3.5 now contains a standard benchmark scene, and available with one click on the menu. This saves a lot of possible confusion on getting command line parameters right on the GUI version of PovRay, but care is still needed when benchmarking it with a console or parallel version of PovRay. Just click menu option Render/Run Benchmark and wait... and wait... Please DO NOT open the benchmark.pov file and render it manually! My PII/400 did it in 4 hours 19 minutes about 270x more demanding than skyvase, but I'm a little concerned about the high start up latency of 6 minutes to set up photons... Each machine in a cluster will probably have to duplicate this effort each time they want to trace a region, and it isn't backward compatible. Should I make another benchmark anyway that isn't so Pov 3.5 specific? Linux and Mac Users: Please use the standard benchmark.ini to run the benchmark in console mode. Further information can be found here: http://www.povray.org/download/benchmark.php. The current Mac GUI release doesn't run the benchmark properly - version 3.51 for Mac to be released late Feb 2003 corrects this problem. |
Skyvase To participate, please download the "standard" skyvase.pov
script file (2600 bytes) If using a console version of PovRay then use the following arguments: povray -i skyvase.pov +v1 -d +ft -x +a0.300 +r3 -q9 -w640 -h480 -mv2.0 +b1000 > results.txt When either skyvase or the new standard benchmark completes, submit your machine/cluster details and times. You should be at least a little familiar with POVRay. Note: Please supply a valid email address for confirmation or questions. It will never be made public and may only be used to inform you of new developments. No email, no listing!
|
Have a listen to some of my music on Garageband Hope you like it, feedback welcome... Andy.

NEW! Graph of New Benchmark results
New Benchmark Top 5 Parallel
| Time: 00:00:24 | Big Bertha | Opteron 8356 2300 MHz. 32 used. OS: Win 2k3 |
| Time: 00:00:32 | monster | Opteron 6378 2400 MHz. 64 used. OS: Linux 4.8.0 |
| Time: 00:00:34 | Dual W5580 | Xeon W5580 3200 MHz. 2 used. OS: Windows 7 Ultimate x64 |
| Time: 00:00:37 | Sun Fire x4170 | Xeon E5540 3 MHz. 2 used. OS: Windows Server 2003 R2 |
| Time: 00:00:38 | monster | AMD Opteron(tm) Processor 6378 2400 MHz. 4 used. OS: Linux 4.8.0 |
New Benchmark Top 5 Single
| Time: 00:00:50 | xeon-ws | XEON w3580 4230 MHz. OS: Win 7 |
| Time: 00:00:54 | xeon-ws | W3580 3948 MHz. OS: Windows 7 64 |
| Time: 00:01:00 | Omega 64 | i5 760 4200 MHz. OS: Win 7 64bit |
| Time: 00:01:04 | self-built i7 | i7 920 3333 MHz. OS: Windows Vista Home Premium 64-bit |
| Time: 00:01:05 | i7 | Intel Xeon W3580 3333 MHz. OS: Windows XP x64 |
Skyvase Top 5 Clusters
| Time: 00:00:01 | DARK STAR 866/24 | Intel P-III 866 MHz. 24 used. OS: kernel 2.2.18_Cluster |
| Time: 00:00:01 | Dual W5580 | Xeon W5580 3200 MHz. 2 used. OS: Windows 7 Ultimate x64 |
| Time: 00:00:01 | SIRIUS | Athlon 76800 MHz. 64 used. OS: Linux 2.4.14 |
| Time: 00:00:01 | TAKERU MyCluster | Xeon dual 2.4GHz/Xeon dual 2.2GHz Total 16CPU 2400 MHz. 16 used. OS: Redhat Linux 7.2 |
| Time: 00:00:02 | MK-81 | Intel Pentium III (96 total) 48000 MHz. 96 used. OS: Linux 2.2.2 |
Skyvase Top 5 Single
| Time: 00:00:01 | i7 | Intel Xeon W3580 3333 MHz. OS: Windows XP x64 |
| Time: 00:00:01 | self-built i7 | i7 920 2670 MHz. OS: Windows Vista Home Premium 64-bit |
| Time: 00:00:01 | Hestia | q6600 3000 MHz. OS: linux |
| Time: 00:00:01 | Custom built | AMD Phenom II X4 955 3200 MHz. OS: Windows 7 Professional 64-bit |
| Time: 00:00:02 | Intel Core2 Duo E8400 3 GHz @ 3.6 GHz 3600 MHz. OS: Windows 7 x64 |
Resources
The Beowulf Project
(Where it all began)
Top Beowulf Clusters
Useful information on the fastest grids in the world.
IEEE Task Force on Cluster Computing (TFCC)
The TFCC is an international forum promoting cluster computing research and education.
Home Supercomputing with Linux
(How to set up a Beowulf cluster)
IBM demonstrates Linux servers matching supercomputer speeds
This was the article that nearly killed my server! :-)
Open-source supercomputer beats Cray
Same story on CNN.
Supercomputer Breaks the $100/GFLOPS Barrier
August 2003 Slashdot Article
If you would like a link here, then please mail me at